
1. Numpy의 특징
1) Matlab과 매우 유사한 문법 사용
2) Python ecosystem의 핵심
- Scipy, Scikit-learn 등 다른 많은 라이브러리에서 Numpy 기능을 내부적으로 활용하고 있음.
3) 빠른 연산 지원
- 일반적으로 파이썬은 느리지만 cpython으로 코딩 된 Numpy는 연산 속도가 빠르다.
4) n차원 배열을 쉽게 조작할 수 있다.
- vector(1차원), matrix(2차원), tensor(3차원 이상)
2. ndarray
1) ndarray
numpy에서는 다차원 행렬 계산을 위해 자체적으로 ndarray라는 자료형을 가지고 있다.
n-dimenstional의 줄임말로 n차원을 의미한다.
dimentions는 axes라고 사용하기도 한다.
import numpy as np ## 개발자들의 십중팔구는 numpy를 np로 축약해서 사용
my_first_array = np.array([0,0.5,1])
print(my_first_array)
print(type(my_first_array))
## 출력
[0. 0.5 1. ]
<class 'numpy.ndarray'>출력결과를 보면 원소들이 모두 float64타입으로 출력된 것을 확인할 수 있는데 원소 중 하나라도 float64타입을 가지고 있으면 원소 전체가 float64타입으로 변환되어 저장된다.
2) ndarray의 연산
ndarray 객체는 배열로 간주하면 되며(행렬과 유사) 관련 연산들을 지원한다.
배열의 덧셈, 뺄셈, 원소별 곱셈, 원소별 나눗셈, 몫, 나머지 연산 등
내적을 하고 싶은 경우는 @ 혹은 dot메소드를 사용하면 된다.
my_second_array = np.array((1,1,1)) ## 튜플로 선언해도 타입은 ndarray타입
## 배열의 연산
print(my_first_array + my_second_array)
print(my_first_array - my_second_array)
print(my_first_array * my_second_array)
print(my_first_array / my_second_array)
print(my_first_array // my_second_array)
print(my_first_array % my_second_array)
## 출력
[1. 1.5 2. ]
[-1. -0.5 0. ]
[0. 0.5 1. ]
[0. 0.5 1. ]
[0. 0. 1.]
[0. 0.5 0. ]
## 내적
A = np.array([[1,2],[3,4]])
B = np.array([[1,1],[2,2]])
print(A@B) ## 배열의 곱(1)
print(A.dot(B)) ## 배열의 곱(2)
print(np.dot(A,B)) ## 배열의 곱(3)
## 출력
[[ 5 5]
[11 11]]
[[ 5 5]
[11 11]]
[[ 5 5]
[11 11]]
ndarray와 스칼라 값 간의 연산이 진행될 때 스칼라 값이 loop를 돌며 하나씩 더하는 것이 아닌 vectorization이 적용되어 스칼라 값을 vector로 만들어 여러 원소들 간의 계산을 빠르게 한다
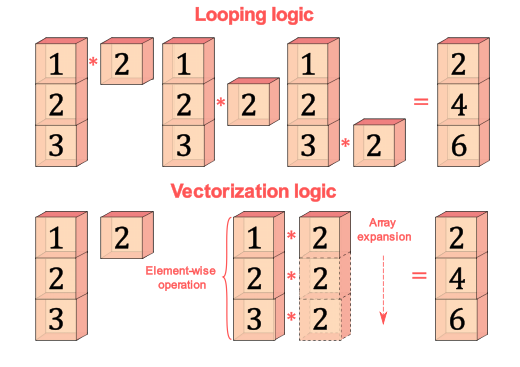
[Looping과 Vectorization의 연산 속도 비교]
[Looping과 Vectorization의 연산 속도 비교]
import numpy as np
x = np.random.rand(100)
y = np.random.rand(100)
%%timeit
for i in range(0, len(x)):
x[i] + y[i]
%%timeit
x+y;
## 결과
33.3 µs ± 1.13 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
854 ns ± 216 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)첫번째 경우는 looping을 사용한 경우로 마이크로초가 단위로 나왔고
두번째 경우는 numpy의 vectorization을 사용한 경우로 나노초가 단위로 나왔다.
두번째 경우(vectorization이 적용된 경우)가 전체 배열을 한 번에 처리해 계산이 빨라지고 내부적으로 C로 구현된 코드라서 메모리 접근 및 연산이 최적화 되어 성능이 첫번째 경우에 비해 향상된 것을 확인할 수 있다.
ndarray는 다양한 수들의 표현이 가능하다
삼각함수: sin, cos, tan 등
Rounding: round, floor, ceil
Exponents and logarithms: exp, log, log10, log2 등
others: sqrt, sign 등
3) ndarray 배열의 정보를 확인하는 법
ndim: ndarray의 차원의 수
shape: 각 차원별 원소의 개수
size: 전체 원소의 개수
len: 가장 바깥 차원의 값
dtype: 데이터 타입
A = np.array([[1,2],[3,4]])
print(A.ndim, A.shape, A.size, len(A))
## 출력
2 (2, 2) 4 2
3. Numpy Arrays의 다양한 생성 방법
1) arange
range 내장 함수와 거의 동일한 기능 제공. 지정된 범위에 따라 ndarray 객체를 생성한다.
- np.arange(start,end-1,step)의 형태로 사용한다.
print(np.arange(5)) ## 0~4
print(np.arange(1,5)) ## 1~4
print(np.arange(1,5,2)) ## 1,3
## 출력
[0 1 2 3 4]
[1 2 3 4]
[1 3]
2) linspace
특정 범위의 수를 균등하게 나누고자 할 때 사용한다.
- np.linspace(start,stop,count) 세개의 파라미터를 받으며 start부터 stop까지 count개의 구간으로 나눈다.
print(np.linspace(1,50), len(np.linspace(1,50))) ## 1부터 50까지 총 50개의 구간
print(np.linspace(1,10,5)) ## 1부터 10까지 총 5개의 구간
## 출력
[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18.
19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29. 30. 31. 32. 33. 34. 35. 36.
37. 38. 39. 40. 41. 42. 43. 44. 45. 46. 47. 48. 49. 50.] 50
[ 1. 3.25 5.5 7.75 10. ]
3) zeros
shape에 맞춰서 float64 타입의 0으로 채워진 ndarray를 생성한다.
zeros_like: 주어진 시퀸스 객체와 동일한 shape으로 int64타입의 0으로 채워진 ndarray 객체 생성
print(np.zeros(5))
C = np.array([[1,2],[3,4],[5,6]])
print(np.zeros_like(C)) ## C와 같은 shape을 가지되 0으로 채우기
d = [1,2]
print(np.zeros_like(d))
e = [1,2,3]
print(np.zeros_like(e))
##출력
[0. 0. 0. 0. 0.]
[[0 0]
[0 0]
[0 0]]
[0 0]
[0 0 0]
4) full
주어진 shape과 값에 맞춰서 ndarray 객체 생성(zeros_like, ones_like의 일반화 버전)
print(np.full((2,3),3)) ## (shape), value
print(np.full(shape = (2,3), fill_value = 3))
## 출력
[[3 3 3]
[3 3 3]]
[[3 3 3]
[3 3 3]]
5) eye, identity
주어진 shape에 맞춰서 identical matrix 객체 생성
eye 메소드의 경우 파라미터 중에서 k=0이 기본값이며, k값을 조절하여 대각의 위치를 조절할 수 있다.
(*identical matrix: 주대각선이 모두 1이고 나머지 원소는 모두 0인 matrix)
# identity
identity = np.identity(3)
# eye
eye = np.eye(4, k=1)
## 출력
[[1. 0. 0.]
[0. 1. 0.]
[0. 0. 1.]]
[[0. 1. 0. 0.]
[0. 0. 1. 0.]
[0. 0. 0. 1.]
[0. 0. 0. 0.]]
6) random.randn
표준정규분포로부터 주어진 shape에 맞춰 난수를 채운 ndarray객체 생성
(*표준정규분포: 평균이 0이고 표준편차가 1인 정규분포)
print(np.random.randn(3)) ## np.random.randn(shape)
print(np.random.randn(3,3))
print(np.random.randn(2,2,2))
## 출력
# 3
[1.8295381 0.1246484 0.96749318]
# 3*3
[[-0.2517882 0.44918559 0.93397383]
[ 0.25034041 -0.2458813 -0.61818323]
[ 0.63617186 -1.27870902 -0.21354979]]
# 2*2*2
[[[-1.00691411 0.4204177 ]
[-0.20299423 -0.51861932]]
[[-0.23013911 -0.60539032]
[ 0.48277194 -0.7843241 ]]]'💂군대 > KAIST ICT Academy' 카테고리의 다른 글
| [Numpy] Broadcasting (0) | 2024.11.03 |
|---|---|
| [Numpy] Array manipulation (0) | 2024.11.02 |
| [후기] 군 장병 KAIST ICT Academy 수료 (7) | 2024.11.02 |
| M12 - 에러 핸들링 (1) | 2024.10.13 |
| M11 - 상속과 오버라이딩 (0) | 2024.10.12 |