
스택과 큐는 데이터를 제한적으로 접근할 수 있는 나열 구조로 가장 기본적인 자료구조 중 하나이다.
1. 스택(Stack)
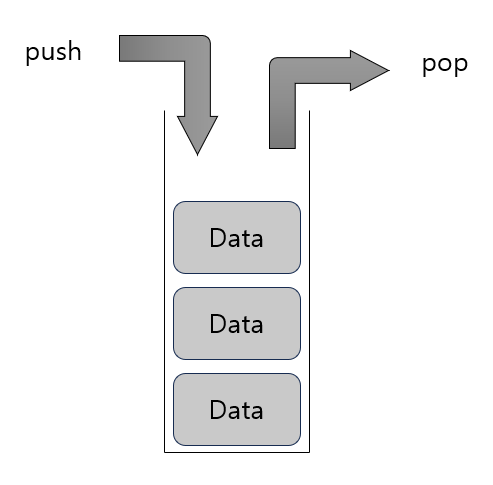
데이터를 차곡차곡 쌓아올린 형태의 자료구조로 후입선출(Last in First Out) 개념이다. 스택에 나중에 들어간 놈이 먼저 나온다고 생각하면 된다.
그림과 같이 Stack에 데이터를 추가하는 작업을 push, 제거하는 작업을 pop 이라고 한다.
StackOverflow(오버플로우): 스택이 가득차서 더 이상의 데이터를 추가할 수 없는 경우
● stack.push(x) - 스택에 데이터를 추가
● stack.pop() - 스택의 최상위 데이터를 삭제
● stack.top() - 스택의 최상위 데이터를 반환
● stack.empty() - 스택이 비었는지 확인
● stack.size() - 스택의 현재 사이즈 반환
C++의 경우 "stack<Data type> stack명" 으로 선언할 수 있다.
#include <stack>
stack<int> stack;
stack.push(1);
stack.top();
stack.pop();
stack.size();
stack.empty();
추천 문제: https://www.acmicpc.net/problem/10828
10828번: 스택
첫째 줄에 주어지는 명령의 수 N (1 ≤ N ≤ 10,000)이 주어진다. 둘째 줄부터 N개의 줄에는 명령이 하나씩 주어진다. 주어지는 정수는 1보다 크거나 같고, 100,000보다 작거나 같다. 문제에 나와있지
www.acmicpc.net
2. 큐(Queue)
스택과 반대로 선입선출(First in First Out) 개념이다. 먼저 집어넣은 데이터가 먼저 나오도록 데이터를 저장하는 형식이다.
그림과 같이 먼저 들어간 데이터가 먼저 나오게 되며 스택과 마찬가지로 큐에 데이터를 삽입하는 작업을 push, 제거하는 작업을 pop한다고 한다.
QueueOverflow(큐 오버플로우): 큐가 가득차서 더 이상의 데이터를 삽입할 수 없는 경우

● queue.push(x) - 큐에 데이터를 추가
● queue.pop() - 큐의 최상위 데이터를 삭제
● queue.front() - 큐의 최상위 데이터를 반환
● queue.empty() - 큐가 비었는지 확인
● queue.back() - 큐의 제일 마지막 데이터 반환
● queue.size() - 큐의 현재 사이즈 반환
C++의 경우 "queue<Data type> queue명" 으로 선언할 수 있다.
#include <queue>
queue<int> q;
q.push(1);
q.front();
q.pop();
q.size();
q.back();
q.empty();
추천문제: https://www.acmicpc.net/problem/10845
10845번: 큐
첫째 줄에 주어지는 명령의 수 N (1 ≤ N ≤ 10,000)이 주어진다. 둘째 줄부터 N개의 줄에는 명령이 하나씩 주어진다. 주어지는 정수는 1보다 크거나 같고, 100,000보다 작거나 같다. 문제에 나와있지
www.acmicpc.net
위의 두 문제를 다 풀어보았다면 추가로 https://www.acmicpc.net/problem/24511 이 문제도 풀어보기를 추천한다.
큐/스택의 개념을 완전히 이해하여 코드를 최적화해야 시간초과(TLE)를 피할수 있을 것이다.
스택과 큐의 기능은 리스트에도 있기 때문에 굳이 왜 사용해야할까 싶지만 스택과 큐는 LIFO/FIFO 개념으로 각각의 역할이 명확하기 때문에 코드의 가독성을 높이고 유지보수하기도 쉬워진다.
또한 각각의 연산에 대해 최적화된 연산을 수행하기 때문에 코드의 실행시간도 줄일수 있다.
'📚알고리즘 > 알고리즘 이론' 카테고리의 다른 글
| 동적 계획법(Dynamic Programming) (1) | 2023.12.23 |
|---|---|
| 분할정복(Divide and Conquer) (4) | 2023.12.19 |
| 이분 탐색(Binary Search) (2) | 2023.12.18 |
| 완전 탐색(Brute-force Search) (1) | 2023.12.18 |
| Big-O Notation (0) | 2023.12.18 |
스택과 큐는 데이터를 제한적으로 접근할 수 있는 나열 구조로 가장 기본적인 자료구조 중 하나이다.
1. 스택(Stack)
데이터를 차곡차곡 쌓아올린 형태의 자료구조로 후입선출(Last in First Out) 개념이다. 스택에 나중에 들어간 놈이 먼저 나온다고 생각하면 된다.
그림과 같이 Stack에 데이터를 추가하는 작업을 push, 제거하는 작업을 pop 이라고 한다.
StackOverflow(오버플로우): 스택이 가득차서 더 이상의 데이터를 추가할 수 없는 경우
● stack.push(x) - 스택에 데이터를 추가
● stack.pop() - 스택의 최상위 데이터를 삭제
● stack.top() - 스택의 최상위 데이터를 반환
● stack.empty() - 스택이 비었는지 확인
● stack.size() - 스택의 현재 사이즈 반환
C++의 경우 "stack<Data type> stack명" 으로 선언할 수 있다.
#include <stack>
stack<int> stack;
stack.push(1);
stack.top();
stack.pop();
stack.size();
stack.empty();
추천 문제: https://www.acmicpc.net/problem/10828
10828번: 스택
첫째 줄에 주어지는 명령의 수 N (1 ≤ N ≤ 10,000)이 주어진다. 둘째 줄부터 N개의 줄에는 명령이 하나씩 주어진다. 주어지는 정수는 1보다 크거나 같고, 100,000보다 작거나 같다. 문제에 나와있지
www.acmicpc.net
2. 큐(Queue)
스택과 반대로 선입선출(First in First Out) 개념이다. 먼저 집어넣은 데이터가 먼저 나오도록 데이터를 저장하는 형식이다.
그림과 같이 먼저 들어간 데이터가 먼저 나오게 되며 스택과 마찬가지로 큐에 데이터를 삽입하는 작업을 push, 제거하는 작업을 pop한다고 한다.
QueueOverflow(큐 오버플로우): 큐가 가득차서 더 이상의 데이터를 삽입할 수 없는 경우
● queue.push(x) - 큐에 데이터를 추가
● queue.pop() - 큐의 최상위 데이터를 삭제
● queue.front() - 큐의 최상위 데이터를 반환
● queue.empty() - 큐가 비었는지 확인
● queue.back() - 큐의 제일 마지막 데이터 반환
● queue.size() - 큐의 현재 사이즈 반환
C++의 경우 "queue<Data type> queue명" 으로 선언할 수 있다.
#include <queue>
queue<int> q;
q.push(1);
q.front();
q.pop();
q.size();
q.back();
q.empty();
추천문제: https://www.acmicpc.net/problem/10845
10845번: 큐
첫째 줄에 주어지는 명령의 수 N (1 ≤ N ≤ 10,000)이 주어진다. 둘째 줄부터 N개의 줄에는 명령이 하나씩 주어진다. 주어지는 정수는 1보다 크거나 같고, 100,000보다 작거나 같다. 문제에 나와있지
www.acmicpc.net
위의 두 문제를 다 풀어보았다면 추가로 https://www.acmicpc.net/problem/24511 이 문제도 풀어보기를 추천한다.
큐/스택의 개념을 완전히 이해하여 코드를 최적화해야 시간초과(TLE)를 피할수 있을 것이다.
스택과 큐의 기능은 리스트에도 있기 때문에 굳이 왜 사용해야할까 싶지만 스택과 큐는 LIFO/FIFO 개념으로 각각의 역할이 명확하기 때문에 코드의 가독성을 높이고 유지보수하기도 쉬워진다.
또한 각각의 연산에 대해 최적화된 연산을 수행하기 때문에 코드의 실행시간도 줄일수 있다.
'📚알고리즘 > 알고리즘 이론' 카테고리의 다른 글
| 동적 계획법(Dynamic Programming) (1) | 2023.12.23 |
|---|---|
| 분할정복(Divide and Conquer) (4) | 2023.12.19 |
| 이분 탐색(Binary Search) (2) | 2023.12.18 |
| 완전 탐색(Brute-force Search) (1) | 2023.12.18 |
| Big-O Notation (0) | 2023.12.18 |